

Quick Answer
To reduce crawl depth on a small website, important pages should be reachable within three clicks from the homepage. A flat site architecture combined with strong internal linking allows search engines to reach pages faster and crawl them more efficiently. When crawl paths become shorter, Googlebot can discover and index pages more consistently.
Symptoms / Situation
When crawl depth becomes too large, the problem usually does not appear immediately in rankings.
Instead, I often notice the first signals inside indexing reports.
During technical SEO audits, I frequently see pages that technically exist but are rarely crawled. The content is published and accessible, yet search engines reach those pages slowly.
Typical signs include:
- new pages taking weeks to be discovered
- articles buried deep inside navigation layers
- crawl activity concentrated only on top-level pages
- slow indexing despite a clean technical setup
These patterns usually relate to how search engines allocate crawling resources, which is closely connected to crawl budget in SEO.
Decision Block
When crawl depth becomes excessive, the issue usually comes from structural design rather than technical errors.
Most cases fall into one of these situations:
- the website architecture contains too many layers
- internal links do not guide crawlers efficiently
- important pages sit too far away from the homepage
Reducing crawl depth helps search engines move through the website faster and improves crawl efficiency.
Introduction
When I audit small websites, one of the first structural improvements I make is to reduce crawl depth so important pages can be reached faster.
Most of the time the content itself is perfectly fine.
The real problem usually lies in the structure.
Search engines navigate websites by following links. If important pages require several steps before they can be reached, crawlers naturally visit them less frequently.
For small websites, a flat architecture works far better than a deep hierarchy.
Instead of long navigation chains, important pages should remain close to the homepage so that crawlers can reach them quickly.
Understanding how search engines discover pages is also part of modern AI crawl optimization, where architecture plays a major role in crawling efficiency.
Causes
Several structural patterns increase crawl depth without website owners realizing it.
Deep navigation layers
Many websites organize content like this:
Homepage → Blog → Category → Subcategory → Article
Each level increases the number of clicks required to reach the page.
Deep navigation layers make it harder to reduce crawl depth, especially when categories and subcategories create long crawl paths.
Weak internal linking
Internal links guide crawlers through the website. When pages link only to nearby content, crawlers must travel deeper before discovering important sections.
Hidden pages
Sometimes pages exist but remain difficult to reach because internal links are missing.
In indexing reports, this behavior often resembles situations similar to discovered currently not indexed pages.
Problem Explanation
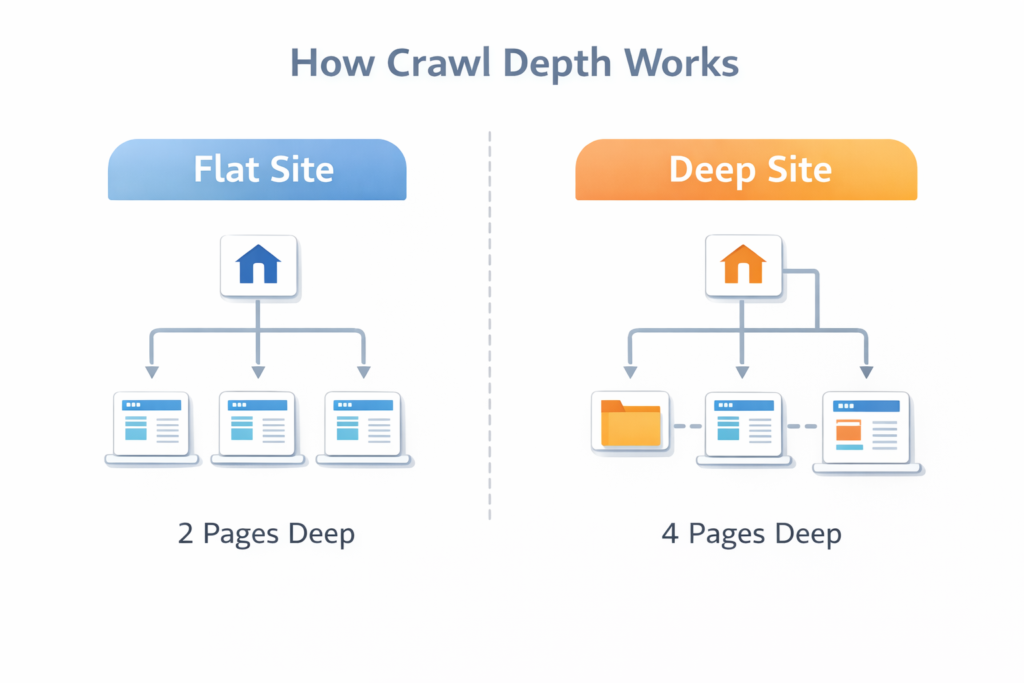
Search engines crawl websites by following links from one page to another.
Each time Googlebot follows a link, it moves deeper into the site structure.
This process creates what is known as the crawl path.
Pages located deeper inside the structure receive less crawling attention because the crawler must travel through multiple steps before reaching them.
When many pages compete for crawling resources, deeper pages naturally receive lower priority.
In some cases, crawl depth issues appear together with indexing inconsistencies, such as indexed not submitted in sitemap reports.
The deeper a page sits inside the structure, the harder it becomes to reduce crawl depth and maintain efficient crawling.
Crawl Depth Impact Table
| Crawl Depth | SEO Impact |
|---|---|
| 1–2 clicks | Ideal crawl accessibility |
| 3 clicks | Acceptable structure |
| 4+ clicks | Higher risk of crawl delay |
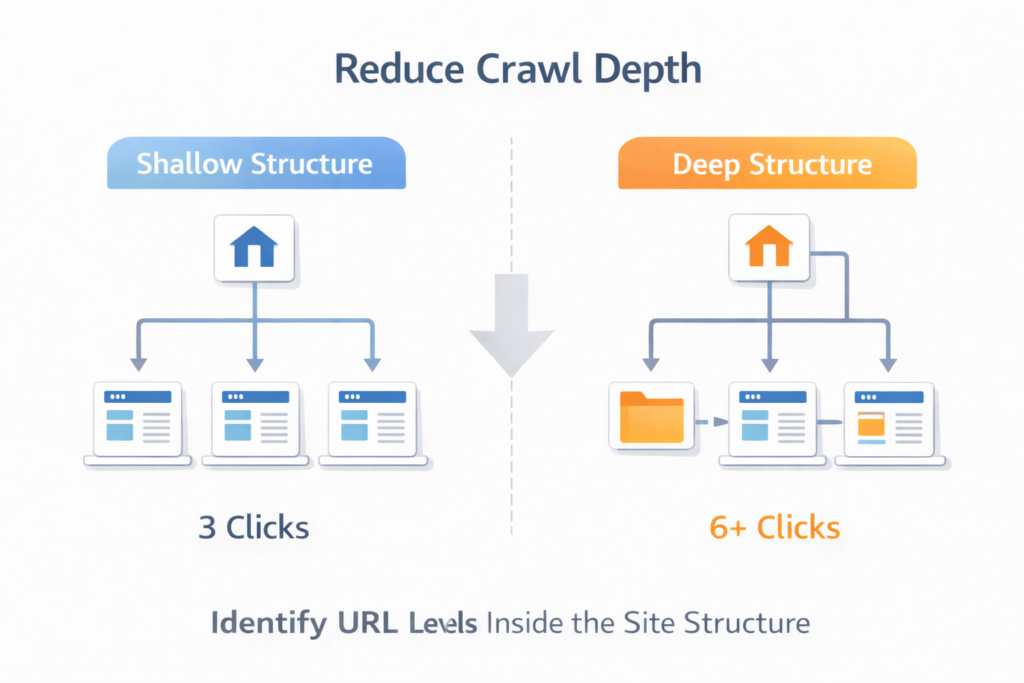
This table shows why reducing structural layers is essential if you want to reduce crawl depth and improve crawl efficiency.
How to Measure Crawl Depth on Your Website
Before reducing crawl depth, I usually measure it first.
Many website owners assume their structure is simple, but once the crawl paths are mapped, the depth is often much greater than expected.
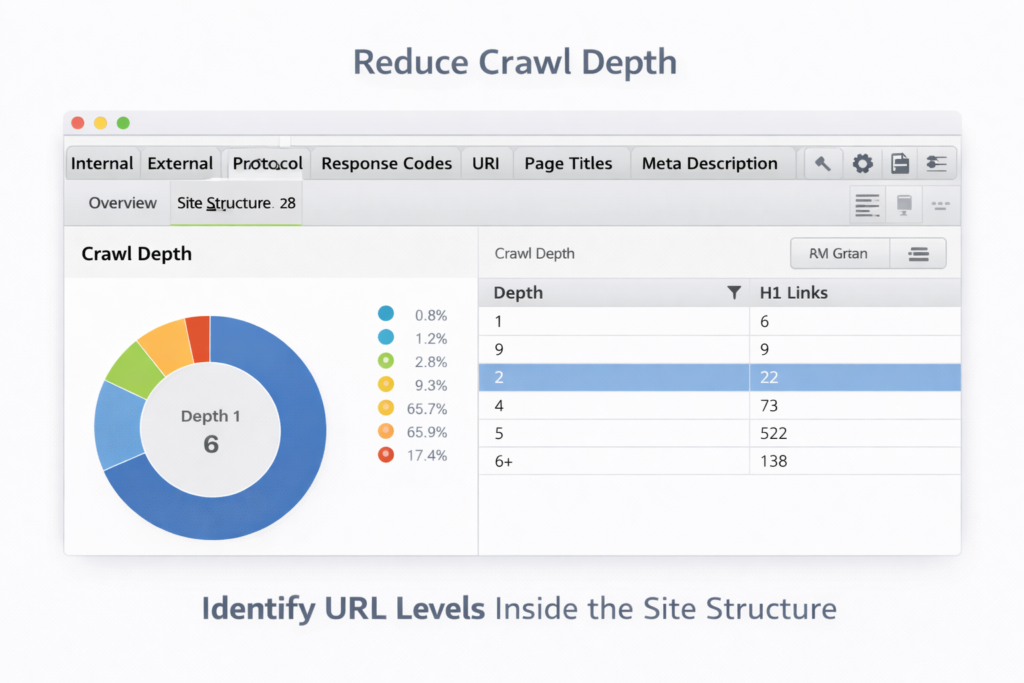
Common ways to evaluate crawl depth include:
- reviewing crawl reports from SEO crawlers
- mapping internal link connections between pages
- counting how many clicks are required to reach important pages
- checking which pages receive the most crawl activity
- verifying discovery signals in indexing reports
Understanding crawl paths helps identify structural issues that are not immediately visible.
Real SEO Scenario
During one technical audit I performed, a website had more than one hundred articles but only about half were indexed.
The structure looked like this:
- Homepage → Blog → Category → Subcategory → Article
Five clicks.
Many articles were buried under multiple navigation layers.
After simplifying the structure and improving internal linking, the path became:
- Homepage → Blog → Article
Two clicks.
Within a few weeks, crawlers began visiting the deeper pages more frequently and indexing improved significantly.
Step-by-Step Fix
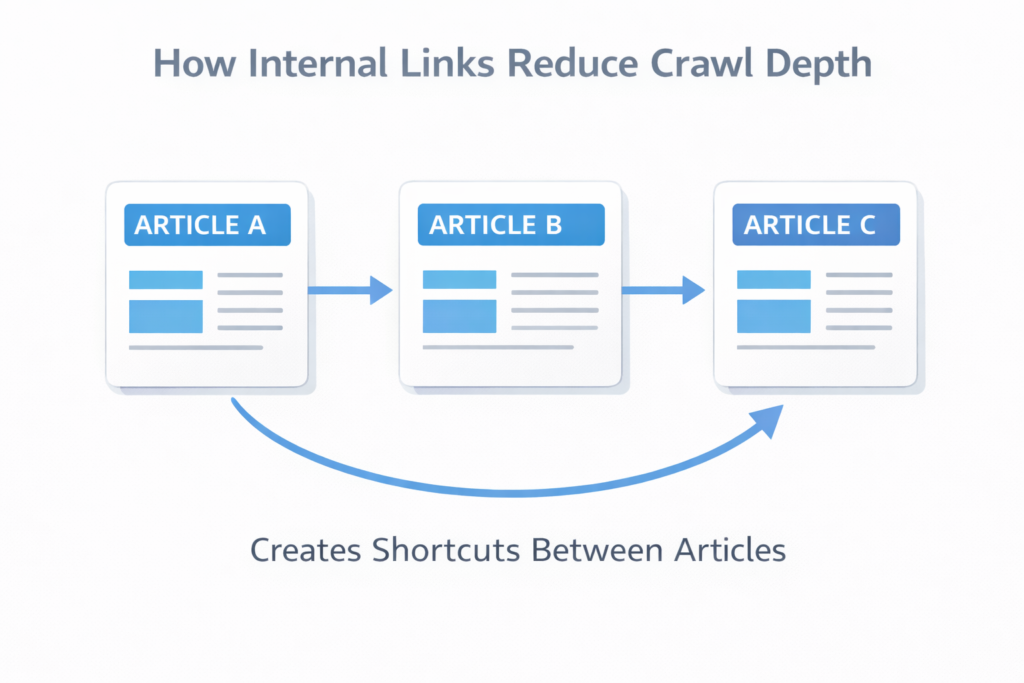
Reducing crawl depth usually requires structural improvements rather than complex technical changes.
Flatten the architecture
Important sections should stay close to the homepage.
A simple structure might look like this:
- Homepage
- Blog
- Guides
- Tools
- Articles
Pages should ideally be reachable within two or three clicks.
Improve internal linking
Internal links create shortcuts that allow crawlers to reach deeper pages faster.
Analyzing internal link distribution using the link analyzer tool helps identify missing connections between pages.
Maintain a clean sitemap
Search engines rely on sitemaps to discover URLs efficiently.
Generating one using the XML sitemap generator ensures important pages are visible to search engines.
Internal Linking Best Practices
When I work on reducing crawl depth, I usually follow a few simple internal linking rules:
- link new articles from strong pages
- connect related pages across categories
- avoid isolating pages inside deep folders
- ensure important pages appear in navigation
- link back to cornerstone pages regularly
These small adjustments can dramatically shorten crawl paths.
Website Structure Comparison
| Structure Type | Crawl Path | SEO Impact |
|---|---|---|
| Flat structure | Homepage → Page | Fast crawling |
| Moderate structure | Homepage → Category → Page | Acceptable |
| Deep structure | Homepage → Category → Subcategory → Page | Slow discovery |
| Complex structure | Multiple nested layers | Crawl inefficiency |
In most small websites I audit, improving structure alone significantly reduces crawl depth.
Technical Insight
Googlebot prioritizes pages using several structural signals.
These include:
- internal linking strength
- crawl history
- sitemap signals
- overall site architecture
Pages located closer to the homepage usually receive stronger crawling signals.
Reducing crawl depth therefore improves crawl efficiency naturally.
Search engines explain how this works in documentation about Google crawling and indexing.
Tool Recommendation
Understanding crawl accessibility often requires verifying which pages are already indexed.
One simple way to do this is by checking URLs using the Google index checker.
Analyzing index coverage together with site structure helps reveal pages that remain hidden from crawlers.
AI Search Summary
Crawl depth represents the number of clicks required to reach a page from the homepage. Pages located deeper inside a site structure usually receive less crawling attention. Reducing crawl depth by flattening site architecture and strengthening internal links helps search engines discover pages earlier and improves indexing efficiency.
FAQs
What is crawl depth in SEO?
Crawl depth is the number of clicks required for a search engine crawler to reach a page starting from the homepage. Pages that are deeper in the structure usually receive less crawl attention and may take longer to be indexed.
What is the ideal crawl depth for SEO?
Most SEO professionals recommend keeping important pages within two to three clicks from the homepage. This helps search engines reach pages faster and improves crawling efficiency.
Does crawl depth affect Google indexing?
Yes. Pages located deeper in a website structure are usually crawled less frequently. If crawl depth is too large, search engines may discover those pages slowly or delay indexing.
How can internal links reduce crawl depth?
Internal links create shortcuts that allow search engine crawlers to reach deeper pages faster. When important pages receive strong internal links, the crawl path becomes shorter.
Can an XML sitemap help reduce crawl depth?
An XML sitemap does not change the structure of a website, but it helps search engines discover pages faster. When combined with strong internal linking, it improves crawling efficiency.
Final Perspective
When people ask me how to reduce crawl depth on a small website, I rarely start with tools.
I start with structure.
Search engines follow the same paths that users follow. When those paths are short and clear, pages are discovered quickly.
When the structure becomes complicated, important pages remain hidden.
Fix the architecture, strengthen internal links, and crawling efficiency usually improves naturally.